MemClaw Owns the Multi-Agent Governed Memory Lane
April 19, 2026 · Caura.AI
Every few years the infrastructure question underneath AI shifts, and the vendors who were perfectly positioned for the old question find themselves competing for a lane that is no longer the lane. It happened with vector databases when retrieval stopped being exotic. It is happening again, right now, to agent memory.
The last two years of memory work assumed one agent, one user, one long conversation. A number of good products were built for that shape, each with real strengths:
- Mem0 — clean API, strong single-agent long-term memory, and a popular open-source community around it.
- Zep — temporal knowledge graphs and entity tracking that handle long conversation history well.
- Letta (formerly MemGPT) — the academic lineage on hierarchical in-context memory management.
- Cognee — thoughtful knowledge-graph pipelines for semantic enrichment.
- Hindsight — observability-flavoured agent memory with strong inspection tooling.
- ByteRover — a sharp focus on developer and code-context memory.
We benchmark inside the same band they do — 77.6% on LoCoMo, 72.5% on LongMemEval, 23 ms p50 search, 96–99% token savings. For a single chatbot, any of the above is a reasonable pick; accuracy across the field is close enough that stack fit usually decides it.
That is last year’s category. The thing enterprises are now deploying — fleets of agents working on behalf of a company, across teams and customers, most acting without a human in the immediate loop — needs something the single-agent products were not designed from day one to provide.
A Different Lane
Multi-agent governed shared memory is not a feature that bolts onto a per-agent memory store. It is a different product built against different constraints: scoped visibility at write time, cross-agent learning at recall time, governance at every layer. We drew a landscape of the capabilities enterprise buyers keep asking about. It looks like this.
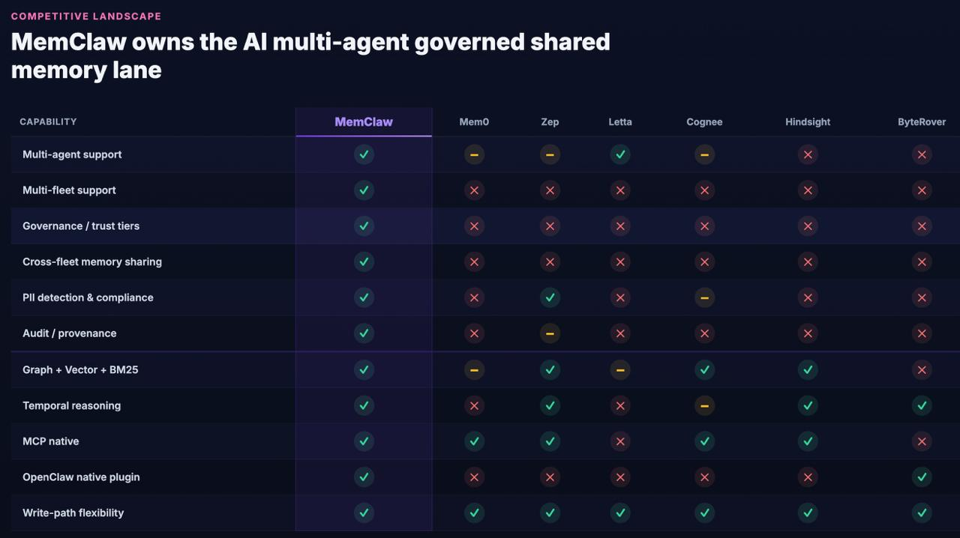
The grid is not a scoreboard. It is a map of which problems a product was built to solve. Every vendor on it made sensible choices for the shape they were designed around. We made different ones, because we were designed around a different shape from day one.
What the New Category Requires
Four things decide whether a memory system is deployable as fleet infrastructure, as opposed to attachable to a single agent. None of them show up on LoCoMo. All of them show up in procurement.
1. Scope is a first-class field on every write
Every memory in MemClaw is stamped at write time as agent-private, fleet-wide, or cross-fleet. Recall respects that scope by default. An HR-fleet memory does not surface in a support-fleet recall because it cannot — not because a filter was added later and the right query has to be written. Scope is structural, not advisory.
2. Agents learn from each other, continuously
When an agent acts on recalled memory, it reports the outcome. Successes reinforce the memories involved. Failures write a preventive rule at fleet scope, so the next forty agents see the lesson before repeating the mistake. This is the loop single-agent memory cannot close, because there is no other agent to close it with.
3. Governance that does not move a recall@k number
Tenant isolation at the data layer. Per-agent trust tiers. PII quarantine before cross-fleet exposure. Full audit log with provenance. None of this improves a single-agent accuracy benchmark. All of it is the difference between a pilot and a production deployment inside a regulated company.
4. Retrieval that can answer the questions fleets ask
Vector + graph + BM25 in one query, with temporal reasoning over memory validity intervals. A fleet does not just ask “what do we know about customer X?” It asks “what did we know about customer X before the migration, which agent learned it, and has that fact been superseded?” Pure-vector stores cannot answer that. Graph-only stores cannot answer the semantic half. MemClaw was built for the combined query because fleets actually issue it.
Why This Is Rearchitecture, Not a Feature Flag
Adding a fleet_id column to a per-agent memory store does not make it fleet-native, any more than adding a tenant_id column makes a SaaS app multi-tenant. The hard parts are structural: where does scope live in the write path, how does outcome reporting feed into weight updates and rule generation, how does permission enforcement happen inside the ranker rather than as a post-filter, how does the audit log stay coherent when one recall touches memories from three fleets.
Several of the vendors above are capable teams and will make the move. But working those choices through a product designed around a single conversation is quarters of work, not an afternoon. Until that lands, the fleet-native category has a different product at its center — and that is the honest reading of the grid, not a claim that anyone else is doing bad work.
The Benchmark That Does Not Exist Yet
LoCoMo and LongMemEval are honest benchmarks for the category they measure. There is no public equivalent for the category we are describing: no standard task that measures whether agent #17’s mistake this morning prevented agents #1 through #40 from repeating it this afternoon, whether a new agent inherits the fleet’s existing knowledge, whether cross-fleet recall respects the permission shape the customer actually configured.
We are working toward one. A fleet-native benchmark is the natural next step once the category is named. Until it exists, the capability grid above is the closest honest snapshot of who built for which shape.
Notes on the Comparison
The capability grid reflects public documentation and our own testing as of April 2026. These are moving targets and we refresh the comparison as products evolve. If something has changed, or we got a row wrong, please tell us at info@caura.ai and we will update it.
Mem0, Zep, Letta, Cognee, Hindsight, and ByteRover are trademarks of their respective owners. This post is our view of the field and is not a statement by or endorsed by any of them. Any factual inaccuracy is unintentional and will be corrected on notice.
Try It
OSS: github.com/caura-ai/caura-memclaw. Apache 2.0, docker compose up, REST and MCP out of the box.
Managed: memclaw.net. Same engine, governance wired in, we run it.
Single-agent memory is a product. Multi-agent governed shared memory is a category. MemClaw is the one defining it.