How Is MemClaw Built?
April 9, 2026 · Caura.AI
MemClaw isn’t a vector database with extra features. It’s a purpose-built governed memory platform that combines a vector store, knowledge graph, and LLM enrichment pipeline into a single system. Here’s how the architecture works.
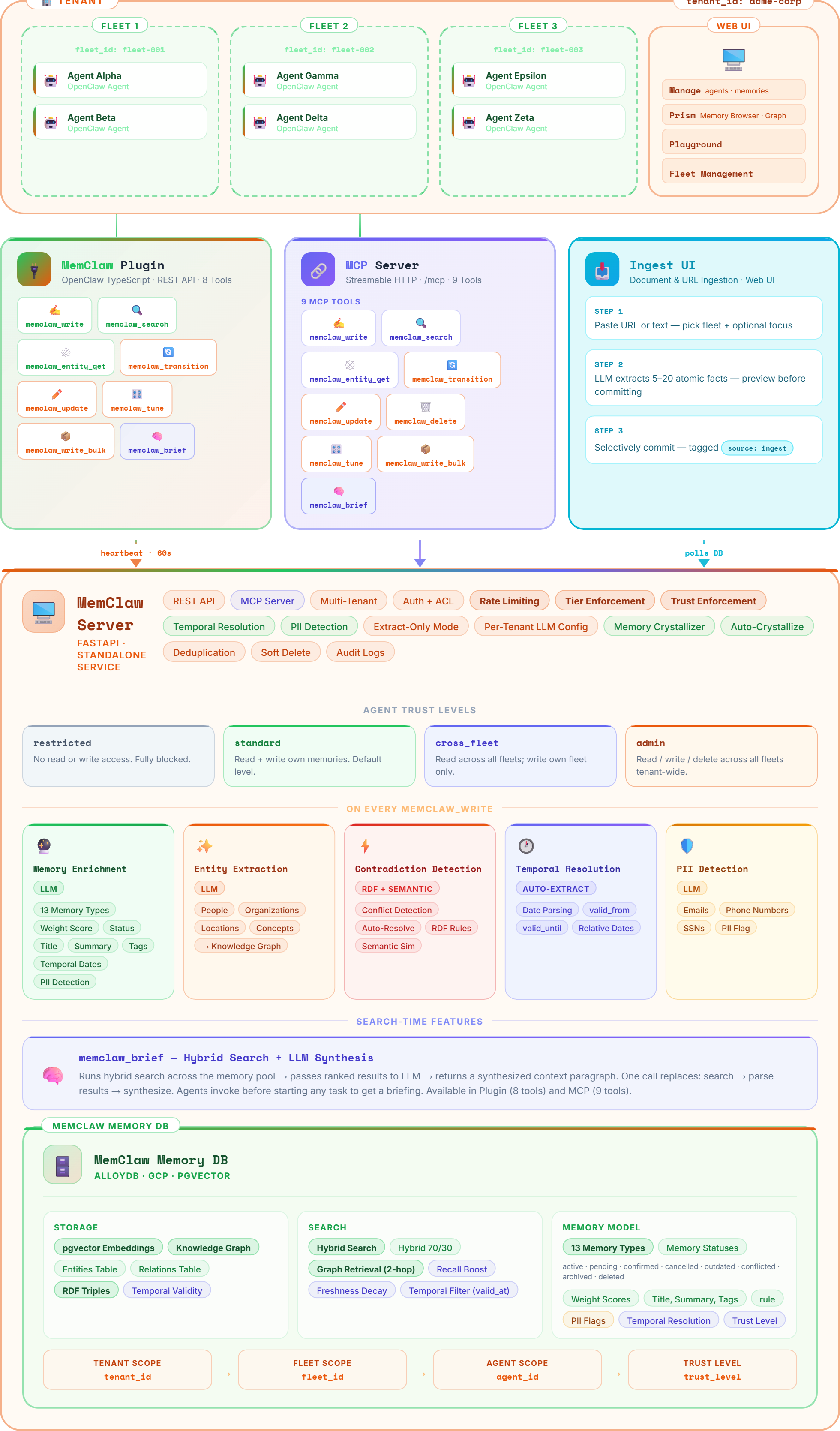
MemClaw architecture — write path, search path, governance, and integration surface
The Write Path
When an agent writes a memory, MemClaw enriches it through an LLM pipeline: auto-classifying type (13 categories), extracting entities and relations into the knowledge graph, detecting contradictions against existing memories, scoring importance, flagging PII, and generating vector embeddings. Long content is auto-chunked into atomic facts. The result is a fully structured, searchable memory created from raw text — the agent just sends content.
The Search Path
Search combines pgvector semantic similarity with full-text keyword matching, then expands results through knowledge graph relations (up to 2 hops). Results are ranked by a composite score: similarity, importance weight, freshness decay, graph boost, and recall boost. Visibility scoping ensures agents only see memories their trust level permits. Agents can also request a one-callmemclaw_brief — an LLM-synthesized context paragraph from the top results.
The Governance Layer
Every operation passes through governance: tenant isolation, fleet boundaries, agent trust levels (4 tiers: restricted, standard, cross-fleet, admin), and visibility scopes (agent, team, org). Cross-fleet access requires explicit trust elevation. Every read, write, and transition is audit-logged with agent identity, timestamps, and full detail. This isn’t a feature toggle — it’s the foundational layer that everything else sits on.
The Knowledge Graph
Every write automatically extracts entities (people, organizations, technologies, products) and relations into a live graph. Search expands through these relations — ask about a customer and you’ll also surface their tech stack, team members, and recent decisions. Fuzzy resolution merges duplicates like “OpenAI” and “Open AI” into canonical entities. The graph densifies with every write, making retrieval progressively smarter.
Memory Quality
Memories aren’t static entries. They move through lifecycle statuses: active, pending, confirmed, outdated, archived, conflicted, expired, deleted. The crystallizer — an LLM-powered consolidation engine — merges near-duplicate clusters into clean atomic facts, archiving source memories with full provenance. Contradiction detection via RDF triples and LLM analysis keeps knowledge clean. Recall boost rewards frequently-used memories, surfacing high-signal knowledge faster.
Integration Surface
Three integration paths converge on the same backend:
- MCP server — Streamable HTTP for Claude Desktop, Claude Code, Cursor, and any MCP-compatible client. Connect with a URL and API key.
- OpenClaw plugin — Fleet deployments with auto-recall before LLM calls, auto-write of summaries, heartbeat monitoring, and OTA updates via Fleet UI.
- REST API — Full CRUD, search, entities, graph, and documents. OpenAPI docs at
/api/docs.
All three paths share the same auth, governance, and 13 tool semantics. No SDK dependency. No install.
The Stack
Under the hood: Python/FastAPI backend, PostgreSQL with pgvector for embeddings and full-text search, Redis for caching and rate limiting, Alembic for migrations, and Next.js for the dashboard and marketing site. Self-hostable in four commands via Docker Compose, or use the managed service at memclaw.net.
Not a wrapper. Not a feature. A governed knowledge system built from the ground up for agent fleets that need to remember, share, and compound intelligence — safely.