Architecture
How MemClaw processes, governs, and connects agent knowledge across your organization.
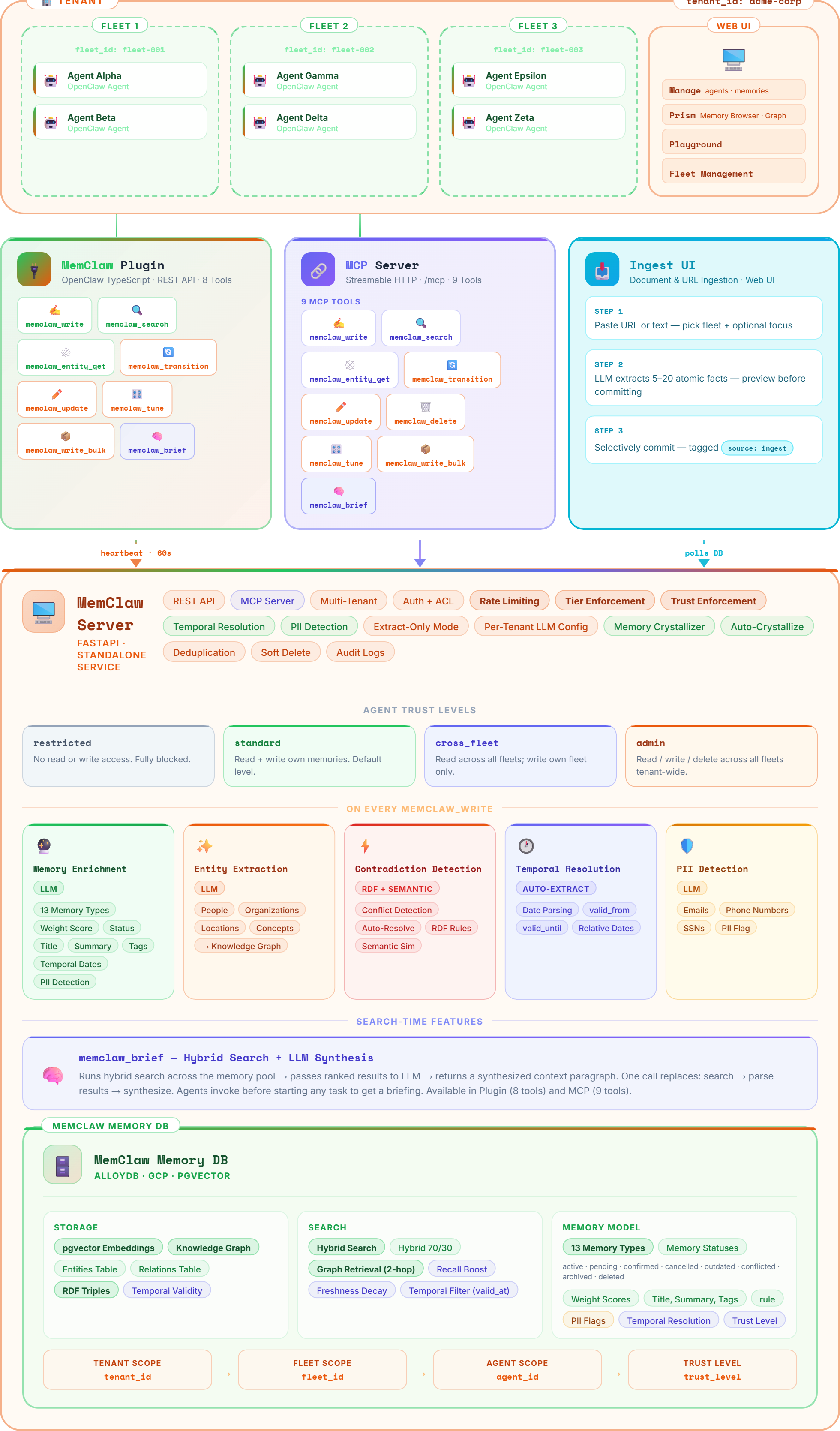
Write Path
When an agent writes a memory, MemClaw enriches it through an LLM pipeline: auto-classifying type, extracting entities and relations into the knowledge graph, detecting contradictions against existing memories, scoring importance, flagging PII, and generating embeddings. Long content is auto-chunked into atomic facts. The result is a fully structured, searchable memory created from raw text.
Search Path
Search combines pgvector semantic similarity with full-text keyword matching, then expands results through knowledge graph relations (up to 2 hops). Results are ranked by a composite score: similarity, importance weight, freshness decay, graph boost, and recall boost. Visibility scoping ensures agents only see memories their trust level permits.
Governance Layer
Every operation passes through the governance layer: tenant isolation, fleet boundaries, agent trust levels, and visibility scopes. Cross-fleet access requires explicit trust elevation. Every read, write, and transition is audit-logged with agent identity, timestamps, and full detail.
Integration Surface
Three integration paths converge on the same backend: the MCP server (Streamable HTTP for Claude Desktop, Claude Code, Cursor, etc.), the OpenClaw plugin (fleet deployments with heartbeat and OTA updates), and the REST API (direct programmatic access). All share the same auth, governance, and tool semantics.